Get duplicate rows and its counts MySQL
Duplicate rows in a MySQL database table can cause data inconsistencies and negatively affect the performance of your application. In order to identify and address these duplicates, you can use SQL queries to get a count of duplicate rows in a table.
SELECT
column_name,
COUNT(column_name)
FROM
table_name
GROUP BY column_name
HAVING COUNT(column_name) > 1;Get duplicate rows and its counts MySQL
To find duplicate rows in a MySQL table, you can use the GROUP BY and HAVING clauses. By utilizing the GROUP BY and HAVING clauses in a SELECT statement, you can group rows with the same values and filter them by the count of occurrences. This can help you identify which rows have duplicates and how many duplicates exist for each row. With this information, you can take appropriate actions to remove or merge duplicate rows and improve the integrity and efficiency of your database.
Here's an example query:
SELECT column1, column2, COUNT(*) as count
FROM my_table
GROUP BY column1, column2
HAVING count > 1;In this query, replace my_table with the name of your table and column1 and column2 with the names of the columns you want to check for duplicates. The COUNT(*) function counts the number of occurrences of each unique combination of values in the specified columns. The HAVING clause filters the results to only show rows with a count greater than 1, which means there are duplicates.
This query will return a list of all the duplicate rows in your table based on the specified columns.
Full Example
Now, Let's understand it by creating a table that has duplicate rows and then getting the duplicate rows count.
here is an example of how to create a table with duplicate rows in MySQL:
CREATE TABLE my_table (
id INT NOT NULL AUTO_INCREMENT,
name VARCHAR(50),
age INT,
PRIMARY KEY (id)
);
INSERT INTO my_table (name, age) VALUES
('John', 25),
('Mary', 30),
('John', 25),
('Bob', 35),
('Mary', 30),
('Bob', 35);In this example, we created a table named my_table with three columns: id, name, and age. We then inserted six rows into the table, where two rows have the same name and age combination, and two other rows also have the same name and age combination. This creates a table with duplicate rows, which can be identified and addressed using SQL queries.
The output of the query in a table format will be:
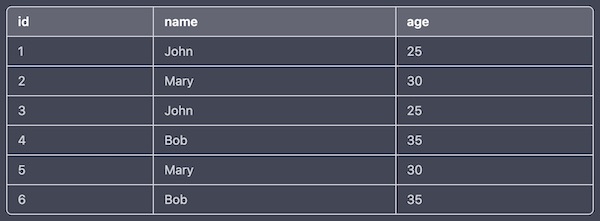
To get the duplicate rows from the my_table table in MySQL, you can use the following SQL query:
SELECT name, age, COUNT(*) AS count
FROM my_table
GROUP BY name, age
HAVING count > 1;
This query groups the rows by their name and age columns and returns only the groups that have a count of more than one, which indicates that there are duplicates. The COUNT(*) function is used to count the number of rows in each group, and the AS count clause renames the resulting column as count for readability. The output of this query will show the name and age values of the duplicate rows, as well as the number of duplicates for each group.