Counting rows in a Pandas Dataframe based on column values
If you have a pandas DataFrame with a column of values and you want to count the number of rows where the value in that column is equal to a certain value, this tutorial will show you how.
import pandas as pd
# create a DataFrame
df = pd.DataFrame({
'name': ['Rachel', 'Jacob', 'Dom', 'Syral', 'Naboi'],
'city': ['Japan', 'NewYork', 'London', 'Itly', 'France'],
'status': ['active', 'inactive', 'active', 'active', 'inactive']
})
print(df)
# get count of rows which has value - active for status column
total_active_users = df[df['status']=='active'].shape[0]
print(f'Total active users are: {total_active_users}')Output
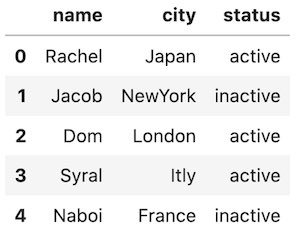
Total active users are: 3The code above creates a DataFrame with three columns ('name', 'city', and 'status').
The DataFrame df is then printed.
The code then gets the count of rows that have the value 'active' in the 'status' column.
This count is then printed.
Syntax
df[df['column_name'] condition].shape(0)Another example is to count the number of rows based on some condition applied on column values.
import pandas as pd
# creating a DataFrame
df = pd.DataFrame({
'name': ['Rachel', 'Jacob', 'Dom', 'Syral', 'Naboi'],
'city': ['Japan', 'NewYork', 'London', 'Itly', 'France'],
'status': ['active', 'inactive', 'active', 'active', 'inactive'],
'salary': [3000, 5000, 2000, 7000, 4000]
})
print(df)
# get the count of rows where salary is greater than 4500
result = df[df['salary'] > 4500].shape[0]
print(f'Total count: {result}')Output
+----+--------+---------+----------+----------+
| | name | city | status | salary |
|----+--------+---------+----------+----------|
| 0 | Rachel | Japan | active | 3000 |
| 1 | Jacob | NewYork | inactive | 5000 |
| 2 | Dom | London | active | 2000 |
| 3 | Syral | Itly | active | 7000 |
| 4 | Naboi | France | inactive | 4000 |
+----+--------+---------+----------+----------+
Total count: 2In the above code example, we are getting the count of rows where the 'salary' column has values greater than 4500.
If you want to get the count of all rows in a pandas DataFrame then you can use the below code.
df.shape[0]Below is the example - we will get the count of rows where name column values contain a specific substring.
import pandas as pd
# creating a DataFrame
df = pd.DataFrame({
'name': ['Rachel', 'Jacob', 'Dom', 'Syral', 'Naboi'],
'city': ['Japan', 'NewYork', 'London', 'Itly', 'France'],
'status': ['active', 'inactive', 'active', 'active', 'inactive'],
'salary': [3000, 5000, 2000, 7000, 4000]
})
# get count - where name column values contain the substring 'o'
result = df[df['name'].str.contains('o')].shape[0]
print(f'Total count: {result}')Output
Total count: 3- [Pandas] Add new column to DataFrame based on existing column
- Change column values condition based in Pandas DataFrame
- Get a column rows as a List in Pandas Dataframe
- Change column orders using column names list - Pandas Dataframe
- Pandas - Delete,Remove,Drop, column from pandas DataFrame
- Check if a column contains zero values only in Pandas DataFrame
- Get column values as list in Pandas DataFrame